Classic Visual Feature Descriptors
We always aim to find feature descriptors that are invariant to luminance, scaling, translation, and rotation, allowing for better performance in tasks such as feature matching and bundle adjustment.
"We wish to identify locations in image scale space that are invariant with respect to image translation, scaling, and rotation, and are minimally affected by noise and small distortions." (Lowe, 1999, p. 2)
However, experiments show that different visual descriptors tend to have similar rates of outliers in feature matching, and the precision differences brought by the application of different feature descriptors in Visual SLAM are negligible.

The results of the experiments prompt us to ponder, what kind of descriptor do we truly need? This question is also the motivation behind writing this blog, which reviews classic visual and point cloud descriptors.

SIFT: Scale-invariant Feature Transform
Scale invariance is mainly ensured by the introduction of convolution kernels of varying sizes during feature detection, which will not be discussed here. How, then, is rotation invariance achieved?
Firstly, during detection, the magnitude and direction of the gradient for each pixel are pre-calculated.
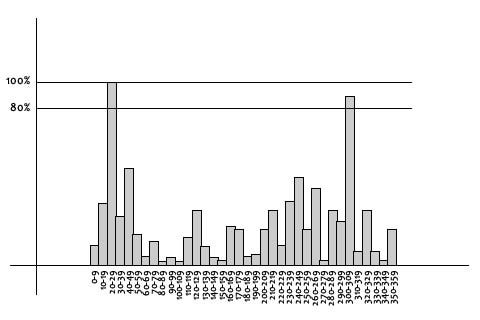
Next, according to the gradient direction of the pixels, the product of the gradient magnitudes is added to the histogram with weights based on the normal distribution probability of the distance from the center point. The direction in the histogram that corresponds to the interval from the maximum value to the 80% of maximum value is identified as the orientation of the feature point (if there are multiple candidate directions within this interval, then multiple feature points with the same other attributes are created and assigned these directions).
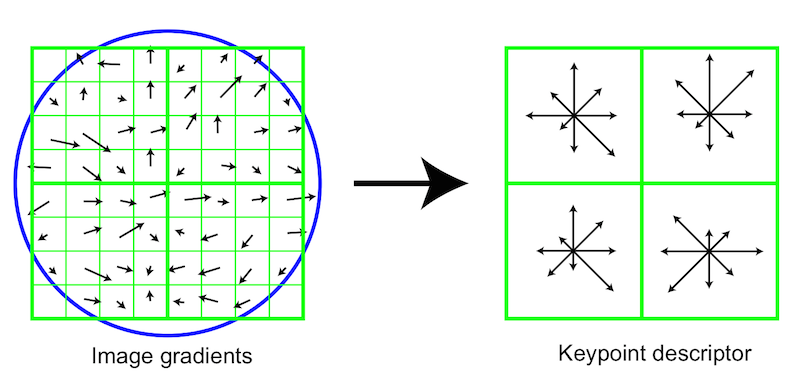
"First the image gradient magnitudes and orientations are sampled around the keypoint location, using the scale of the keypoint to select the level of Gaussian blur for the image. In order to achieve orientation invariance, the coordinates of the descriptor and the gradient orientations are rotated relative to the keypoint orientation." (Lowe, 2004, p. 15)
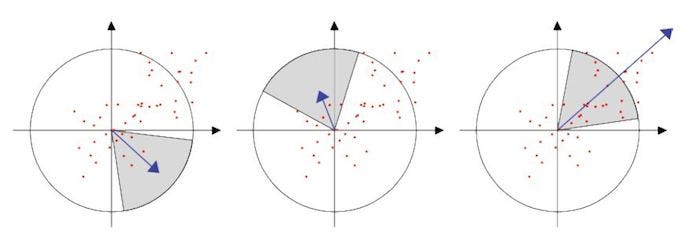
To pursue rotation invariance, all gradients are rotated so that the main gradient (the one with the longest magnitude) points upward. At the same time, to avoid errors caused by luminance changes, gradient magnitudes that exceed a certain threshold are clipped and then normalized.
SURF: Speeded Up Robust Features
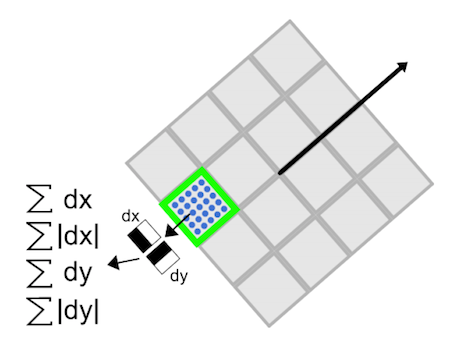
Compared to SIFT, which uses histograms to find the main orientation, SURF determines the main orientation of the feature point by calculating the Harr wavelet responses within a radius of
Around the feature point, a square box with a side length of
BRIEF: Binary Robust Independent Elementary Features
The idea behind BRIEF is very straightforward.
"Our approach is inspired by earlier work [9, 15] that showed that image patches could be effectively classified on the basis of a relatively small number of pairwise intensity comparisons." (Hutchison et al., 2010, p. 3)
Define the binary intensity comparison test as
The results of the binary intensity tests are combined in a predetermined order (which can be randomly selected like G I, G II, G III, or systematically selected like G V) to form an intensity code:

BRISK: Binary Robust Invariant Scalable Keypoints
BRISK basically continues the idea of binary intensity tests.
For
All point pairs constitute a set
The gradient of the feature points is given by the average gradient of the long-range point pairs:
Similarly, to pursue rotation invariance, all points are rotated around the feature point, and then a boolean descriptor is constructed from the short-range pairs based on binary intensity tests, similar to BRIEF.
Experimental Results
Several studies have evaluated the performance of different feature descriptors in Visual SLAM applications. Here we summarize some key findings:
Performance Evaluation of Visual SLAM Using Several Feature Extractors
In a study by Klippenstein and Zhang (2009), Harris, KLT, and SIFT were evaluated using average normalized error and accumulated uncertainty metrics:
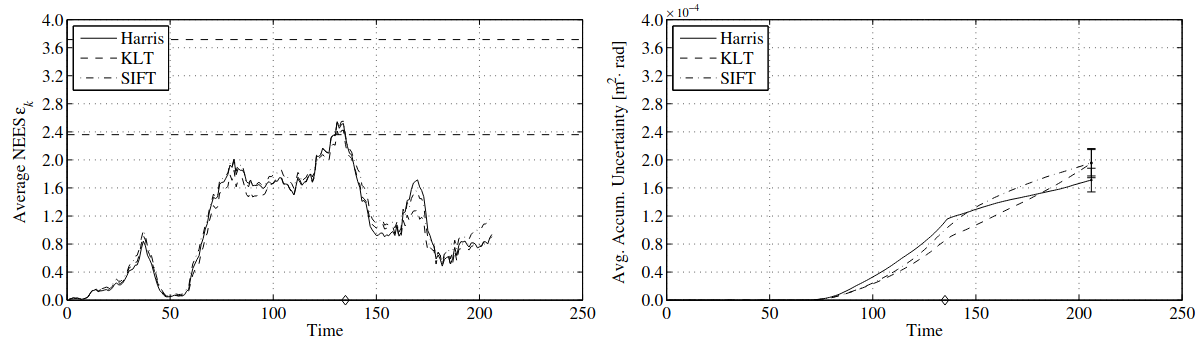
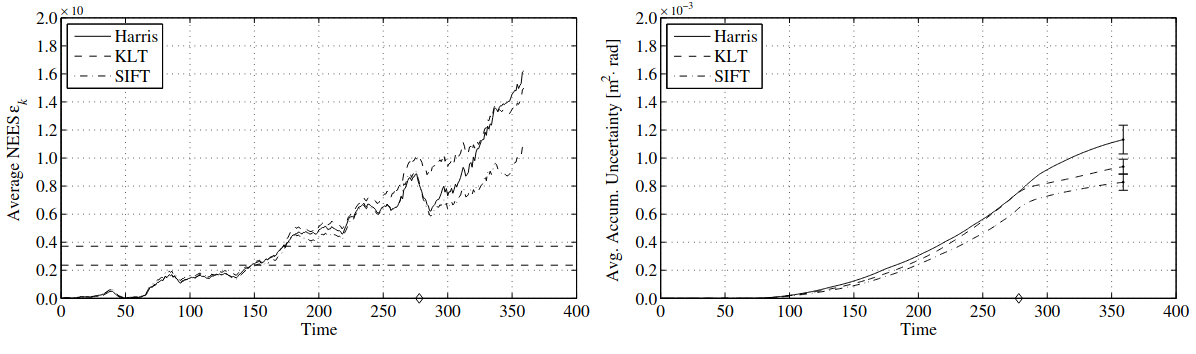
The results showed that in most indoor scenarios, there were no significant differences in accumulated uncertainty among the three feature extractors. The average normalized error followed similar trends, with nearly identical performance. SIFT showed slightly better performance in terms of accumulated uncertainty, though the study did not include feature matching comparisons.
Evaluation of RGB-D SLAM System
Endres et al. (2012) conducted experiments on the FR1 dataset and found that:
- SIFT performed well but was computationally expensive
- ORB was computationally efficient and handled viewpoint changes well
- SURF required careful threshold adjustment to maintain an appropriate number of feature points
- Too few SURF features led to inaccurate motion estimation and failures
- Too many features slowed down matching and increased false positives

The study also revealed that when there were incorrect edges in the graph, the mapping results deteriorated. The authors suggested future improvements in keypoint matching strategies, such as adding feature dictionaries, pruning unmatched features, and directly using keypoints as landmarks for nonlinear optimization.
Comparison of Feature Descriptors for Visual SLAM
Hartmann et al. (2013) conducted experiments on both RGBD datasets and their own datasets, finding that:
- SIFT achieved the best performance but was the most computationally intensive
- BRIEF performed best among binary descriptors
- In most cases, the choice of descriptor had minimal impact on accuracy
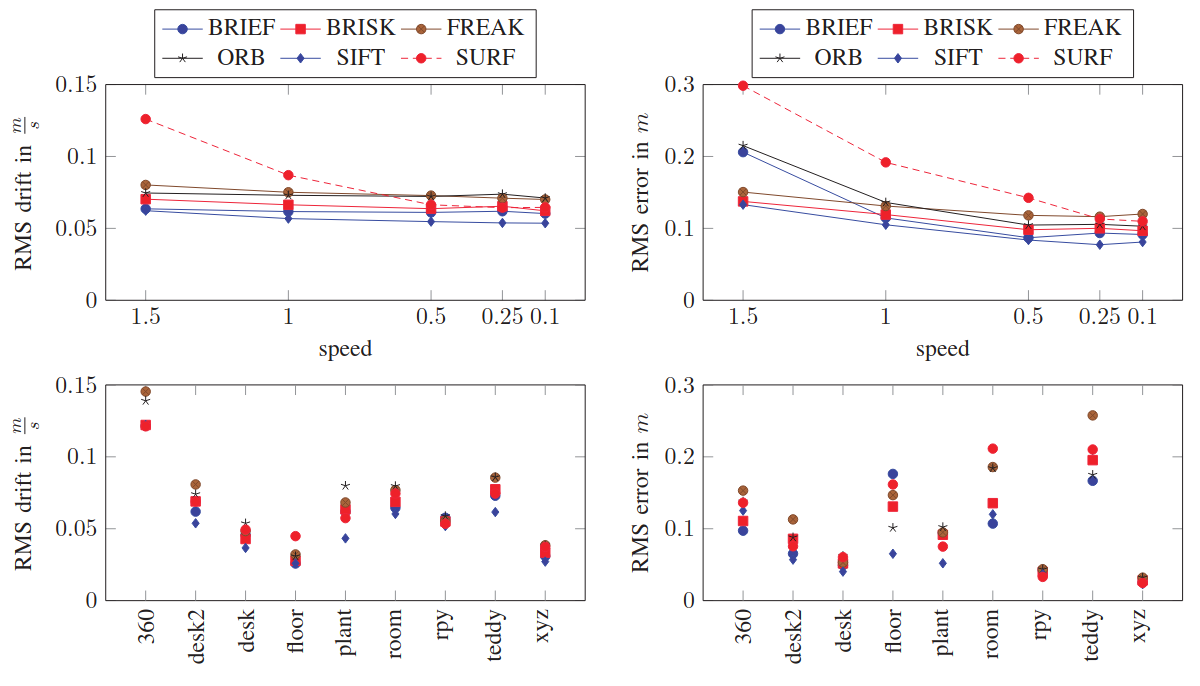
These experimental results suggest that while different feature descriptors have their own characteristics, their impact on the overall performance of Visual SLAM systems might be less significant than initially thought. The choice of descriptor should be based on a balance between computational efficiency and the specific requirements of the application.