Factor Graph for Pose Estimation
Slide: Overview of factor graphs in pose estimation, emphasizing their benefits over Kalman Filters for handling complex dependencies. Covers dynamic Bayesian networks, information forms, and smoothing for efficient state estimation.
Kalman Filter
Markov Chain
The classic Kalman Filter corresponds to a simple Markov Chain:
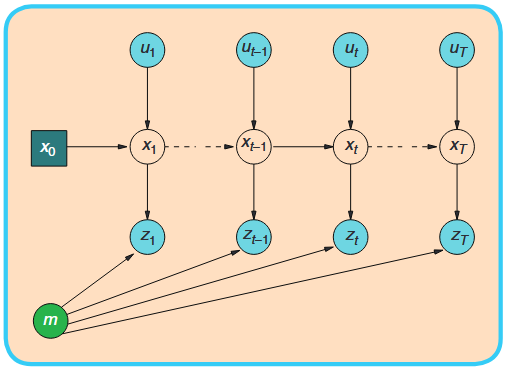
Core Assumptions:
- Markov Property: The current state
depends only on the immediate previous state and input - Conditional Independence: Given the current state
, the observation is independent of all other states and observations.
Scenario 1: Spatio-Temporal Constraints
A robot revisits a location, observing the same landmark
These two observations create a direct constraint between pose
Scenario 2: Physical Constraints
When tracking multiple objects, they may be subject to physical interaction constraints
The Kalman Filter, designed for a single Markov chain, cannot natively represent this cross-object dependency.
Factor Graph
Dynamic Bayesian Networks
Dynamic Bayesian Networks (DBNs) provide a more flexible framework than a simple Markov chain for representing probabilistic dependencies across time.
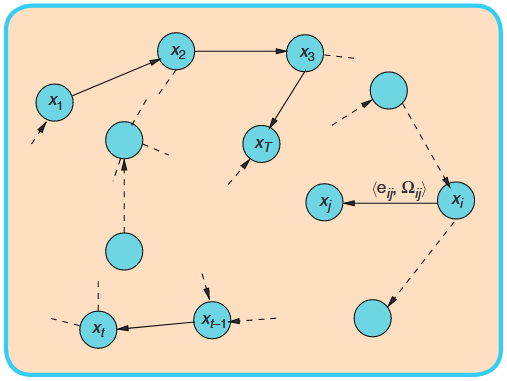
Extensions:
- Arbitrary Time-Span Dependencies: States can depend on states several steps back.
- Complex Inter-Variable Constraints: Multiple variables within a time slice can be interconnected.
- Hierarchical State Representations: States can be decomposed into sub-states with their own dependencies.
Dynamic Bayesian Networks (cont.)
It is a bipartite graph consisting of two types of nodes:
- Variable Nodes: Represent the unknown quantities we wish to estimate.
- Factor Nodes: Represent a constraint or a measurement on the set of variables they are connected to.
Goal: Find the most probable assignment of the variables that maximizes the product of all factors.
Under Gaussian assumptions, this becomes a nonlinear least-squares problem:
Unified View
The Dual Information Form
| Operation | Covariance Form | Information Form |
|---|---|---|
| Marginalization | ||
| Conditioning |
The Dual Information Filter
| Kalman Filter | Information Filter | |
|---|---|---|
| Prediction Step | ||
| Update Step |
Factor Graph with Information Form
The global nonlinear optimization problem
can be linearized at current estimation
where:
is the Jacobian matrix of measurement function is the residual vector
Factor Graph with Information Form (cont.)
| Local Information Form | Global Information Form |
|---|---|
where
The optimal update is then:
From Filtering to Smoothing
Kalman Filter, Information Filter, and Factor Graph are fundamentally solving the same problem: state estimation under Gaussian assumptions. They are probabilistically equivalent.
Despite mathematical equivalence, FG-based smoothing dominates modern applications because:
- It naturally encodes arbitrary constraints;
- It exploits sparse structure for efficient solving;
- It's batch-based update enabling non-linear optimization;
- It corrects past states by future evidence.