Report for Cyber Planner Code Report
We have already launched our report for Cyber Planner from Next Innovation STEM Center. You can also find a copy here. And the source code is available in our Github repository.
While Cyber Planner Code Report v0.1.0 (C++ Version) is mainly focused on the Math derivation, Report for Cyber Planner Code Report emphasize the corresponding code of the equation and highlight some details in the implementation. I believe it would bring you a different perspective to our work and enhance your understaning in numerical optimization.



Convex Polytope Set
Any object can be represented by a finite convex polytope set. And a convex polytope can be represented by a group of linear inequalities. If a point is inside the polytope, it should satisfied:

Distance from Point to Polytope
If the point is inside the polytope, the distance is the negative minimum distance to any support hyperplane of the polytope. Which is given by:
Otherwise, we are going to find a point inside the polytope, which has the minimum distance to the original point.
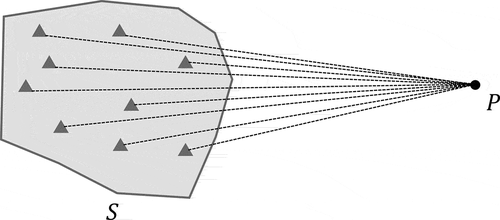
It refers to the Eq. 6 in report and can be solved by LDQP (Low Dimensional Quadratic Programming) easily.
Click me to toggle the code
class Polygon {
private:
// Ax <= b
Eigen::MatrixX2d A;
Eigen::VectorXd b;
public:
bool isPointInside(Eigen::Vector2d p) {
return (this->A * p - this->b).maxCoeff() <= 0;
}
double distanceToPoint(Eigen::Vector2d p) {
if (this->isPointInside(p)) {
double result = INFINITY;
for (int i = 0; i < this->points.size(); i++) {
result = std::min(result,
(b(i) - A.row(i).dot(p)) / (A.row(i).norm() + 1e-20));
}
return -result;
}
if (A.rows() == 1) {
return (A.row(0).dot(p) - b(0)) / (A.row(0).norm() + 1e-20);
}
Eigen::Vector2d x = p;
sdqp::sdqp<2>(2 * Eigen::MatrixXd::Identity(2, 2), -2 * p, A, b, x);
return (p - x).norm();
}
};Distance from Polytope to Polytope
The distance between two polytopes is the minimum distance between any two points in the two polytopes. If the two polytopes are intersected, it is easy. The distance is defined as the minimum distance from a point contained in another polytope to that polytope.
If the two polytopes are not intersected, the distance is the minimum distance between any point in the first polytope and any point in the second polytope.
A LDQP is defined as
Click me to toggle the code
class Polygon {
private:
// Ax <= b
Eigen::MatrixX2d A;
Eigen::VectorXd b;
public:
bool isPolygonIntersect(Polygon poly) {
// check if the two polygons intersect
for (int i = 0; i < this->points.size(); i++) {
Eigen::Vector2d p1 = this->points[i];
Eigen::Vector2d p2 = this->points[(i + 1) % this->points.size()];
for (int j = 0; j < poly.points.size(); j++) {
Eigen::Vector2d q1 = poly.points[j];
Eigen::Vector2d q2 = poly.points[(j + 1) % poly.points.size()];
double d = (p1.x() - p2.x()) * (q1.y() - q2.y()) -
(p1.y() - p2.y()) * (q1.x() - q2.x());
if (d == 0) {
continue;
}
double t = ((p1.x() - q1.x()) * (q1.y() - q2.y()) -
(p1.y() - q1.y()) * (q1.x() - q2.x())) /
d;
double u = -((p1.x() - p2.x()) * (p1.y() - q1.y()) -
(p1.y() - p2.y()) * (p1.x() - q1.x())) /
d;
if (t >= 0 && t <= 1 && u >= 0 && u <= 1) {
return true;
}
}
}
// check if one polygon contains another
bool inside = true;
for (Eigen::Vector2d p : this->points) {
if (!poly.isPointInside(p)) {
inside = false;
break;
}
}
if (inside) {
return true;
}
for (Eigen::Vector2d p : poly.points) {
if (!this->isPointInside(p)) {
return false;
}
}
return true;
}
double distanceToPolygon(Polygon poly) {
Eigen::Vector4d x = Eigen::Vector4d::Zero();
int n1 = this->points.size();
int n2 = poly.points.size();
if (this->isPolygonIntersect(poly)) {
double result = 0;
for (int i = 0; i < n1; i++) {
if (poly.isPointInside(this->points[i])) {
result = std::min(result, poly.distanceToPoint(this->points[i]));
}
}
for (int i = 0; i < n2; i++) {
if (this->isPointInside(poly.points[i])) {
result = std::min(result, this->distanceToPoint(poly.points[i]));
}
}
return result == 0 ? -INFINITY : result;
}
Eigen::Matrix4d Q;
Eigen::Vector4d c;
Q << 2, 0, -2, 0, 0, 2, 0, -2, -2, 0, 2, 0, 0, -2, 0, 2;
c << 0, 0, 0, 0;
Eigen::MatrixX4d c_A = Eigen::MatrixX4d::Zero(n1 + n2, 4);
Eigen::VectorXd c_b = Eigen::VectorXd::Zero(n1 + n2);
for (int i = 0; i < n1; i++) {
c_A(i, 0) = this->A(i, 0);
c_A(i, 1) = this->A(i, 1);
c_b(i) = this->b(i);
}
for (int i = 0; i < n2; i++) {
c_A(i + n1, 2) = poly.A(i, 0);
c_A(i + n1, 3) = poly.A(i, 1);
c_b(i + n1) = poly.b(i);
}
sdqp::sdqp<4>(Q, c, c_A, c_b, x);
return (x.head(2) - x.tail(2)).norm();
}
};Artificial Potential Field
Potential in Grid
To avoid A Star Algorithm finding a path close to the obstacles, we can add a potential field to the grid. The potential field is defined by a 2 pass DP (dynamic programming). The first pass is to calculate the distance from the current point to the nearest obstacle whose index is less than the current point. The second pass is to calculate the distance from the current point to the nearest obstacle by mixing the first pass and the distance from the current point to the nearest obstacle whose index is greater than the current point.
Click me to toggle the code
void getGridMap(ObjectType type, std::vector<std::vector<double>>& map) {
assert(type != ObjectType::ENV);
Object env = Object(ObjectType::ENV);
Object arm = Object(type);
const double obstacle = OBSTACLE_OFFSET;
const double reduce = OBSTACLE_FIELD_REDUCTION;
map = std::vector<std::vector<double>>(
ELEVATOR_GRID_NUMS, std::vector<double>(ARM_GRID_NUMS, true));
// bound of the map
for (int tt = 0; tt < ELEVATOR_GRID_NUMS; ++tt) {
map[tt][0] = obstacle * reduce;
map[tt][ARM_GRID_NUMS - 1] = obstacle * reduce;
}
for (int rr = 0; rr < ARM_GRID_NUMS; ++rr) {
map[0][rr] = obstacle * reduce;
map[ELEVATOR_GRID_NUMS - 1][rr] = obstacle * reduce;
}
// first pass
for (int tt = 1; tt < ELEVATOR_GRID_NUMS - 1; ++tt) {
for (int rr = 1; rr < ARM_GRID_NUMS - 1; ++rr) {
Eigen::Vector2d tr = getTR(tt, rr);
if (env.intersect(arm.armTransform(tr.x(), tr.y()))) {
map[tt][rr] = obstacle;
} else {
double max_val = map[tt - 1][rr - 1];
if (map[tt - 1][rr] > max_val) max_val = map[tt - 1][rr];
if (map[tt][rr - 1] > max_val) max_val = map[tt][rr - 1];
if (map[tt - 1][rr - 1] > max_val) max_val = map[tt - 1][rr - 1];
map[tt][rr] = max_val * reduce;
}
}
}
// second pass
for (int tt = ELEVATOR_GRID_NUMS - 2; tt > 0; --tt) {
for (int rr = ARM_GRID_NUMS - 2; rr > 0; --rr) {
if (map[tt][rr] == obstacle) continue;
double max_val = map[tt + 1][rr + 1];
if (map[tt + 1][rr] > max_val) max_val = map[tt + 1][rr];
if (map[tt][rr + 1] > max_val) max_val = map[tt][rr + 1];
if (map[tt + 1][rr + 1] > max_val) max_val = map[tt + 1][rr + 1];
map[tt][rr] =
map[tt][rr] > max_val * reduce ? map[tt][rr] : max_val * reduce;
}
}
// ignore the value less than 1
// for (int tt = 0; tt < ELEVATOR_GRID_NUMS; ++tt) {
// for (int rr = 0; rr < ARM_GRID_NUMS; ++rr) {
// if (map[tt][rr] < 1) {
// map[tt][rr] = 0;
// }
// }
// }
return;
}Lipschitz Continuous
After gaining a heuristic path, we are going to smooth it and minimize it's stretch energy. The stretch energy can be integrated by the second derivative of the cubic spline interpolated path. However, although the term of the stretch energy and the exponential of the negative distance between two polygons can form a Lipschitz continuous function, but the gradient of the function cannot be solved in analytical form. The numerical form consume too much time and is not practical.

So we use another approximation method to smooth the path, which is presented in the Eq. 8 in the report.
Click me to toggle the code
class Smooth {
private:
int n;
Eigen::VectorXd x, x0; // [t0, t1, ..., tn, r0, r1, ..., rn]'
std::vector<Eigen::Vector2d> path;
private:
static double loss(void* instance, const Eigen::VectorXd& optX,
Eigen::VectorXd& optG) {
Smooth* smooth = static_cast<Smooth*>(instance);
double res = 0;
optG = Eigen::VectorXd::Zero(optX.size());
// length potential field
for (int i = 0; i < smooth->n - 1; ++i) {
double d = pow(optX(i) - optX(i + 1), 2);
optG(i) += 2 * d;
optG(i + 1) += -2 * d;
res += d;
d = pow(optX(i + smooth->n) - optX(i + smooth->n + 1), 2);
optG(i + smooth->n) += 2 * d;
optG(i + smooth->n + 1) += -2 * d;
res += d;
}
// smoothness potential field
for (int i = 1; i < smooth->n - 1; ++i) {
double d = pow(optX(i - 1) - 2 * optX(i) + optX(i + 1), 2);
optG(i - 1) += 2 * d;
optG(i) += -4 * d;
optG(i + 1) += 2 * d;
res += d;
d = pow(optX(i + smooth->n - 1) - 2 * optX(i + smooth->n) + optX(i + smooth->n + 1), 2);
optG(i + smooth->n - 1) += 2 * d;
optG(i + smooth->n) += -4 * d;
optG(i + smooth->n + 1) += 2 * d;
res += d;
}
// penalty term
for (int i = 1; i < smooth->n - 1; ++i) {
res += .5 * pow(optX(i) - smooth->x0(i), 2);
res += .5 * pow(optX(i + smooth->n) - smooth->x0(i + smooth->n), 2);
optG(i) += (optX(i) - smooth->x0(i));
optG(i + smooth->n) += (optX(i + smooth->n) - smooth->x0(i + smooth->n));
}
optG(0) = 0;
optG(smooth->n - 1) = 0;
optG(smooth->n) = 0;
optG(2 * smooth->n - 1) = 0;
return res;
}
};Augumented Lagrangian Method
Iteration
Eq. 30 and Eq. 31 in the report are the objective function and the gradient of it. The corresponding code is shown below.
Click me to toggle the code
class Topp {
private:
static double loss(void* instance, const Eigen::VectorXd& optX,
Eigen::VectorXd& optG) {
Topp* topp = static_cast<Topp*>(instance);
double res = topp->f.dot(optX);
optG = topp->f;
// linear equality constraints
Eigen::VectorXd resEq = topp->G * optX - topp->h + topp->lambda / topp->rho;
res += topp->rho / 2 * resEq.squaredNorm() * LINEAR_EQ_COEFF;
optG += topp->rho * topp->G.transpose() * resEq * LINEAR_EQ_COEFF;
// linear inequality constraints
Eigen::VectorXd resIneq = max(topp->P * optX - topp->q + topp->eta / topp->rho, 0);
res += topp->rho / 2 * resIneq.squaredNorm() * LINEAR_INEQ_COEFF;
optG += topp->rho * topp->P.transpose() * resIneq * LINEAR_INEQ_COEFF;
// second order cone constraints
for (int i = 0; i < topp->n_soc; ++i) {
Eigen::VectorXd resSoc = socProjection(topp->mus[i] / topp->rho - topp->As[i] * optX - topp->bs[i]);
res += topp->rho / 2 * resSoc.squaredNorm() * SOC_COEFF;
optG -= topp->rho * topp->As[i].transpose() * resSoc * SOC_COEFF;
}
// quadratic equality constraints
for (int i = 0; i < topp->n_quadeq; ++i) {
double resQuadeq = (optX.transpose() * topp->Js[i]).dot(optX) - topp->rs[i].dot(optX) + topp->nus[i] / topp->rho;
res += topp->rho / 2 * resQuadeq * resQuadeq * QUAD_EQ_COEFF;
optG += topp->rho * resQuadeq * (2 * topp->Js[i] * optX - topp->rs[i]) * QUAD_EQ_COEFF;
}
return res;
}
};The projection of a vector to a second order cone is in the Eq. 21 in the report. The corresponding code is shown below.
Eigen::VectorXd socProjection(const Eigen::VectorXd& v) {
if (v.rows() == 1) {
return v;
}
double v0 = v(0);
Eigen::VectorXd v1 = v.tail(v.rows() - 1);
if (v0 > v1.norm()) {
return v;
} else if (v0 < -v1.norm()) {
return Eigen::VectorXd::Zero(v.rows());
} else {
Eigen::VectorXd Pk = Eigen::VectorXd::Zero(v.rows());
Pk(0) = v1.norm();
Pk.tail(v.rows() - 1) = v1;
Pk *= (v0 + v1.norm()) / 2 / v1.norm();
return Pk;
}
}Variables Update
The update of the dual variables is shown in the Eq. 32 in the report. The corresponding code is shown below.
for (int i = 0; i < n_soc; ++i) {
mus[i] = socProjection(mus[i] - rho * (As[i] * x + bs[i]));
}
for (int i = 0; i < n_quadeq; ++i) {
nus[i] = nus[i] + rho * (x.transpose() * Js[i] * x - rs[i].dot(x));
}
lambda = lambda + rho * (G * x - h);
eta = max(eta + rho * (P * x - q), 0);
rho = std::min(rho * (1 + GAMMA), BETA);
'%20stroke-opacity='1'%20stroke-miterlimit='10'%20d='M%20651.333785%2033.896852%20L%20824.748667%20184.231618%20L%20983.679599%20334.134614%20L%201053.155457%20408.791723%20L%201113.564127%20483.134816%20L%201163.06077%20557.203146%20L%201183.157741%20594.060678%20L%201199.879049%20630.839706%20L%201212.949931%20667.500978%20L%201222.134875%20704.044494%20L%201227.276874%20740.470255%20L%201228.218919%20758.643883%20L%201228.061911%20776.77826%20L%201224.332981%20812.929257%20L%201215.854571%20848.923247%20L%201202.351919%20884.799481%20L%201193.677249%20902.698346%20L%201183.668016%20920.518707%20L%201130.560199%20991.211374%20L%201059.239501%201059.980698%20L%20875.933141%201186.725075%20L%20662.010301%201290.585595%20L%20552.379752%201330.779538%20L%20445.693095%201361.474521%20L%20345.483001%201381.375233%20L%20298.890999%201386.909751%20L%20255.24289%201389.264865%20L%20215.009695%201388.283567%20L%20178.544682%201383.808851%20L%20161.94113%201380.236928%20L%20146.397379%201375.72296%20L%20132.070436%201370.266946%20L%20125.358362%201367.166046%20L%20122.100454%201365.517467%20L%20118.92105%201363.790383%20L%20107.106229%201356.411027%20L%2096.547469%201348.050372%20L%2087.244769%201338.747673%20L%2083.005564%201333.72343%20L%2079.119627%201328.542179%20L%2072.250545%201317.473144%20L%2066.559019%201305.619071%20L%2062.045051%201292.901457%20L%2060.239464%201286.267886%20L%2058.70864%201279.438056%20L%2055.372229%201250.391652%20L%2056.43203%201218.597615%20L%2061.691784%201184.409213%20L%2071.072988%201148.022704%20L%20101.414704%201069.754421%20'%20transform='matrix(0.0995175,%200,%200,%20-0.0995175,%200.247308,%20141.623329)'/%3e%3cpath%20fill='none'%20stroke-width='5'%20stroke-linecap='round'%20stroke-linejoin='round'%20stroke='rgb(0%25,%200%25,%200%25)'%20stroke-opacity='1'%20stroke-miterlimit='10'%20d='M%20101.414704%201069.754421%20L%20146.279623%20985.833864%20L%20204.372431%20898.262882%20L%20274.594075%20809.082571%20L%20446.164118%20634.136865%20L%20651.333785%20477.168528%20L%20881.153643%20350.895174%20L%201130.834962%20253.197202%20L%201396.374047%20178.383086%20L%201673.767205%20120.682797%20L%201959.089246%2074.444062%20L%202248.375729%2033.896852%20'%20transform='matrix(0.0995175,%200,%200,%20-0.0995175,%200.247308,%20141.623329)'/%3e%3cpath%20fill='none'%20stroke-width='5'%20stroke-linecap='round'%20stroke-linejoin='round'%20stroke='rgb(100%25,%200%25,%200%25)'%20stroke-opacity='1'%20stroke-miterlimit='10'%20d='M%20651.333785%2033.896852%20L%201183.668016%20920.518707%20L%20118.92105%201363.790383%20L%20651.333785%20477.168528%20L%202248.375729%2033.896852%20'%20transform='matrix(0.0995175,%200,%200,%20-0.0995175,%200.247308,%20141.623329)'/%3e%3cpath%20fill='none'%20stroke-width='46.0536'%20stroke-linecap='round'%20stroke-linejoin='round'%20stroke='rgb(100%25,%200%25,%200%25)'%20stroke-opacity='1'%20stroke-miterlimit='10'%20d='M%20651.333785%2033.896852%20L%20651.333785%2033.896852%20'%20transform='matrix(0.0995175,%200,%200,%20-0.0995175,%200.247308,%20141.623329)'/%3e%3cpath%20fill='none'%20stroke-width='46.0536'%20stroke-linecap='round'%20stroke-linejoin='round'%20stroke='rgb(100%25,%200%25,%200%25)'%20stroke-opacity='1'%20stroke-miterlimit='10'%20d='M%201183.668016%20920.518707%20L%201183.668016%20920.518707%20'%20transform='matrix(0.0995175,%200,%200,%20-0.0995175,%200.247308,%20141.623329)'/%3e%3cpath%20fill='none'%20stroke-width='46.0536'%20stroke-linecap='round'%20stroke-linejoin='round'%20stroke='rgb(100%25,%200%25,%200%25)'%20stroke-opacity='1'%20stroke-miterlimit='10'%20d='M%20118.92105%201363.790383%20L%20118.92105%201363.790383%20'%20transform='matrix(0.0995175,%200,%200,%20-0.0995175,%200.247308,%20141.623329)'/%3e%3cpath%20fill='none'%20stroke-width='46.0536'%20stroke-linecap='round'%20stroke-linejoin='round'%20stroke='rgb(100%25,%200%25,%200%25)'%20stroke-opacity='1'%20stroke-miterlimit='10'%20d='M%20651.333785%20477.168528%20L%20651.333785%20477.168528%20'%20transform='matrix(0.0995175,%200,%200,%20-0.0995175,%200.247308,%20141.623329)'/%3e%3cpath%20fill='none'%20stroke-width='46.0536'%20stroke-linecap='round'%20stroke-linejoin='round'%20stroke='rgb(100%25,%200%25,%200%25)'%20stroke-opacity='1'%20stroke-miterlimit='10'%20d='M%202248.375729%2033.896852%20L%202248.375729%2033.896852%20'%20transform='matrix(0.0995175,%200,%200,%20-0.0995175,%200.247308,%20141.623329)'/%3e%3c/svg%3e)
